########################################################
## Open Data Kooperation: univie & Parlament ##########
## Showcase 5: Anfragen: Regierung & Opposition #######
## code by Laurenz Ennser-Jedenastik & Daniel Bliem ###
### Kontakt: laurenz.ennser@univie.ac.at ###############
########################################################
# Leere die Arbeitsumgebung
rm(list = ls())
# Laden der erforderlichen Pakete. Falls nicht installiert, bitte mit 'install.packages("Paket")' installieren
library(httr)
library(jsonlite)
library(RJSONIO)
library(RCurl)
library(httr2)
library(purrr)
library(tibble)
library(rjson)
library(tidyverse)
library(gridExtra)
library(officer)
library(flextable)
library(openxlsx)
library(extrafont)
library(lubridate)
library(grid)
library(stringr)
library(scales)
library(forcats)
# Definieren der URL für die POST-Anfrage
req <- request("https://www.parlament.gv.at/Filter/api/filter/data/101?js=eval&showAll=true")
# Senden der POST-Anfrage mit definiertem Body
t1 <-
req %>%
req_body_raw('{
"NRBR": [
"NR"
],
"GP_CODE": [
"XXVII",
"XXVI",
"XXV",
"XXIV",
"XXIII",
"XXII",
"XXI",
"XX",
"XIX"
],
"VHG": [
"J_JPR_M"
],
"DOKTYP": [
"J"
]
}
') %>%
req_perform()
# Die Antwort in einen Datenframe laden
df1 <- t1 %>% resp_body_json()
# Eine Schleife erstellen, um herunterladbare URLs aus den relativen Links der JSON-Antwort zu erhalten
nrows1 <- length(df1$rows)
vorne <- "https://www.parlament.gv.at"
hinten <- "?json=true"
all.urls <- rep(NA, nrows1)
all.num <- rep(NA, nrows1)
all.type <- rep(NA, nrows1)
all.GP <- rep(NA,nrows1)
# Definieren des Arbeitsverzeichnisses, aus dem JSON Files gezogen werden
setwd("Pfad/zu/Ihrem/Arbeitsverzeichnis")
# Iterieren durch die Reihen, um aus den Links herunterladbare URLs zu machen
for (i in 1:nrows1) {
all.urls[i] <- paste0(vorne, df1[["rows"]][[i]][[15]], hinten)
all.num[i] <- df1[["rows"]][[i]][[3]]
all.type[i] <- df1[["rows"]][[i]][[6]]
all.GP[i] <- df1[["rows"]][[i]][[1]]
download.file(all.urls[i], destfile = paste0(all.GP[i], "_", all.num[i],"_", all.type[i], ".json"))
print(i)
}
# Erstellen der leeren Variablen für den Dataframe
files.in.dir <- list.files(path = "Pfad/Zu/Ihrem/Arbeitsverzeichnis")
files.in.dir <- files.in.dir[grep(".json", files.in.dir)] # Sicherstellen, dass nur JSON-Files in der Liste sind
df01 <- as.data.frame(rep(NA, length(files.in.dir)))
df01$name <- NA
df01$fraktion <- NA
df01$person_url <-NA
df01$person_2 <- NA
df01$person_url_2 <- NA
df01$frak_2 <- NA
df01$topic <- NA
df01$topic_2 <- NA
df01$topic_3 <- NA
df01$topic_4 <- NA
df01$topic_5 <- NA
df01$headword <- NA
df01$headword_2 <- NA
df01$headword_3 <- NA
df01$headword_4 <- NA
df01$headword_5 <- NA
df01$EuroVoc <- NA
df01$party <- NA
df01$einlangen <- NA
df01$beantwortung <- NA
df01$titel <- NA
df01$citation <- NA
df01$GP <- NA
df01$date <- NA
colnames(df01) <- c('name', 'person_url', 'party', 'topic','topic_2', 'EuroVoc', 'date_einlagen','date_beantwortung')
count.files <- length(files.in.dir)
# Funktion zur Ermittlung des Labels
get_label <- function(bubble) {
if (!is.null(bubble[["label"]])) {
return(bubble[["label"]])
} else {
return(NA)
}
}
# Iterieren durch alle Dateien im Verzeichnis
# und extrahieren relevanter Informationen für jedes Mitglied, die dann den erstellten leeren Variablen zugeordnet werden
for (i in 1:count.files) {
# Lese die JSON-Datei für jedes Mitglied ein
getfile <- fromJSON(file = files.in.dir[i])
# Ausgebens des Namens der Datei
print(files.in.dir[i])
# Extrahieren der passenden Daten der JSON-Datei für jede Variable und speichern dieser im Dataframe
df01$name[i] <- getfile[["content"]][["names"]][[1]][["name"]]
df01$fraktion[i] <- getfile[["content"]][["names"]][[1]][["frak_code"]]
df01$person_url[i] <- getfile[["content"]][["names"]][[1]][["url"]]
topics <- vector("list", length = 5)
if (!is.null(getfile[["content"]][["topics"]]) && !is.null(getfile[["content"]][["topics"]][["data"]][["bubbles"]])) {
for (j in 1:length(getfile[["content"]][["topics"]][["data"]][["bubbles"]])) {
topics[[j]] <- get_label(getfile[["content"]][["topics"]][["data"]][["bubbles"]][[j]])
}
}
headwords <- vector("list", length = 5)
if (!is.null(getfile[["content"]][["headwords"]]) && !is.null(getfile[["content"]][["headwords"]][["data"]][["bubbles"]])) {
for (j in 1:length(getfile[["content"]][["headwords"]][["data"]][["bubbles"]])) {
headwords[[j]] <- get_label(getfile[["content"]][["headwords"]][["data"]][["bubbles"]][[j]])
}
}
df01$topic[i] <- if (!is.null(topics[[1]])) topics[[1]] else NA
df01$topic_2[i] <- if (length(topics) >= 2 && !is.null(topics[[2]])) topics[[2]] else NA
df01$topic_3[i] <- if (length(topics) >= 3 && !is.null(topics[[3]])) topics[[3]] else NA
df01$topic_4[i] <- if (length(topics) >= 4 && !is.null(topics[[4]])) topics[[4]] else NA
df01$topic_5[i] <- if (length(topics) >= 5 && !is.null(topics[[5]])) topics[[5]] else NA
df01$headword[i] <- if (!is.null(headwords[[1]])) headwords[[1]] else NA
df01$headword_2[i] <- if (length(headwords) >= 2 && !is.null(headwords[[2]])) headwords[[2]] else NA
df01$headword_3[i] <- if (length(headwords) >= 3 && !is.null(headwords[[3]])) headwords[[3]] else NA
df01$headword_4[i] <- if (length(headwords) >= 4 && !is.null(headwords[[4]])) headwords[[4]] else NA
df01$headword_5[i] <- if (length(headwords) >= 5 && !is.null(headwords[[5]])) headwords[[5]] else NA
if (!is.null(getfile) && !is.null(getfile[["content"]]) && !is.null(getfile[["content"]][["eurovoc"]]) &&
!is.null(getfile[["content"]][["eurovoc"]][["data"]]) && !is.null(getfile[["content"]][["eurovoc"]][["data"]][["bubbles"]][[1]])) {
df01$EuroVoc[i] <- getfile[["content"]][["eurovoc"]][["data"]][["bubbles"]][[1]][["label"]]
} else {
df01$EuroVoc[i] <- NA
}
if(!is.null(getfile[["content"]][["stages"]][[1]][["date"]])){
df01$einlangen[i] <- getfile[["content"]][["stages"]][[1]][["date"]]
} else{
df01$einlangen[i] <- getfile[["content"]][["phase"]][[1]][["stages"]][[1]][["date"]]
}
df01$titel[i] <- getfile[["content"]][["title"]]
df01$citation[i] <- getfile[["content"]][["zitation"]]
df01$GP[i] <- getfile[["content"]][["gp_code"]]
eingebracht_an_index <- NULL
if (!is.null(getfile[["content"]][["names"]])) {
for (j in 1:length(getfile[["content"]][["names"]])){
if (!is.null(getfile[["content"]][["names"]][[j]][["funktext"]]) &&
getfile[["content"]][["names"]][[j]][["funktext"]] == "Eingebracht an") {
eingebracht_an_index <- j
break
}
}
}
if (!is.null(eingebracht_an_index)) {
if (!is.null(getfile[["content"]][["names"]][[eingebracht_an_index]][["frak_code"]])) {
df01$person_2[i] <- getfile[["content"]][["names"]][[eingebracht_an_index]][["name"]]
df01$person_url_2[i] <- getfile[["content"]][["names"]][[eingebracht_an_index]][["url"]]
df01$frak_2[i] <- getfile[["content"]][["names"]][[eingebracht_an_index]][["frak_code"]]
} else {
df01$person_2[i] <- getfile[["content"]][["names"]][[eingebracht_an_index]][["name"]]
df01$person_url_2[i] <- getfile[["content"]][["names"]][[eingebracht_an_index]][["url"]]
df01$frak_2[i] <- NA
}
} else {
df01$person_2[i] <- NA
df01$person_url_2[i] <- NA
df01$frak_2[i] <- NA
}
}
# Löschen leerer Spalten
df01 <- df01[,-c(3,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25)]
# Speichern des erstellten Dataframes
save(df01, file = "Ihr Dateiname.RData")
# falls Laden der Daten notwendig ist: load("Pfad/zu/Ihrer Datei.RData")
# Hinzufügen einer zusätzliche Jahresvariable, indem das Jahr aus dem "einlangen"-Datum extrahiert wird
df01$year <- format(as.Date(df01$einlangen, format = "%d.%m.%Y"), "%Y")
df01$year <- as.numeric(df01$year)
# Filtern des Untersuchungszeitraums: Bis zur Sommerpause 2023 (10.07.)
df01 <- df01 %>%
filter(as.Date(einlangen, format = "%d.%m.%Y") <= as.Date("2023-07-10"))
## Erstellen einer Variable, die anzeigt, ob eine Partei in einem gegebenen Jahr in der Regierung oder Opposition ist
# Etablieren der Regierungsperioden für alle Parteien
govperiods_VP <- data.frame(
Partei = "V",
Startdatum = as.Date(c("17.12.1990", "07.01.2020"), format = "%d.%m.%Y"),
Enddatum = as.Date(c("28.05.2019", "31.12.2024"), format = "%d.%m.%Y")
)
govperiods_SP <- data.frame(
Partei = "S",
Startdatum = as.Date(c("17.12.1990", "11.01.2007"), format = "%d.%m.%Y"),
Enddatum = as.Date(c("03.02.2000", "17.12.2017"), format = "%d.%m.%Y")
)
govperiods_FP <- data.frame(
Partei = "F",
Startdatum = as.Date(c("04.02.2000", "18.12.2017"), format = "%d.%m.%Y"),
Enddatum = as.Date(c("10.01.2007", "27.05.2019"), format = "%d.%m.%Y")
)
govperiods_Gruene <- data.frame(
Partei = "G",
Startdatum = as.Date(c("07.01.2020"), format = "%d.%m.%Y"),
Enddatum = as.Date(c("31.12.2024"), format = "%d.%m.%Y")
)
govperiods_BZOE <- data.frame(
Partei = "B",
Startdatum = as.Date(c("17.04.2005"), format = "%d.%m.%Y"),
Enddatum = as.Date(c("10.01.2007"), format = "%d.%m.%Y")
)
# Funktion zur Bestimmung des Regierungsstatus einer Partei zu einem bestimmten Zeitpunkt
get_government_status <- function(party_periods, date) {
government_status <- 0
if (any(party_periods$Startdatum <= date & party_periods$Enddatum >= date)) {
government_status <- 1 # Die Partei war zu dem angegebenen Datum in der Regierung (1)
}
return(government_status)
}
# Hinzufügen der Variable zum Dataframe
df01$gov <- sapply(seq_along(df01$fraktion), function(i) {
party <- df01$fraktion[i]
date <- as.Date(df01$einlangen[i], format = "%d.%m.%Y")
if (party == "V") {
party_periods <- govperiods_VP
} else if (party == "S") {
party_periods <- govperiods_SP
} else if (party == "F") {
party_periods <- govperiods_FP
} else if (party == "G") {
party_periods <- govperiods_Gruene
} else if (party == "B") {
party_periods <- govperiods_BZOE
} else {
party_periods <- NULL
}
if (!is.null(party_periods)) {
get_government_status(party_periods, date)
} else {
0
}
})
# Erstellen einer neue Variable für alle Regierungsperioden
# Erstellen eines Dataframes für die Regierungsperioden
regierungsperioden <- data.frame(
regper = c(
"Regierung Vranitzky III", "Regierung Vranitzky IV", "Regierung Vranitzky V",
"Regierung Klima", "Regierung Schüssel I", "Regierung Schüssel II",
"Regierung Gusenbauer", "Regierung Faymann I", "Regierung Faymann II",
"Regierung Kern", "Regierung Kurz I", "Regierung Bierlein",
"Regierung Kurz II", "Regierung Schallenberg", "Regierung Nehammer"
),
startdatum_regper = c(
"17.12.1990", "29.11.1994", "12.03.1996",
"28.01.1997", "04.02.2000", "28.02.2003",
"11.01.2007", "02.12.2008", "16.12.2013",
"17.05.2016", "18.12.2017", "03.06.2019",
"07.01.2020", "11.10.2021", "06.12.2021"
),
enddatum_regper = c(
"28.11.1994", "11.03.1996", "27.01.1997",
"03.02.2000", "27.02.2003", "10.01.2007",
"01.12.2008", "15.12.2013", "16.05.2016",
"17.12.2017", "28.05.2019", "06.01.2020",
"10.10.2021", "05.12.2021", "31.12.2024" # Für die laufende Regierung voraussichtliches Enddatum
)
)
# Zusätzlich: Dauer der Regierungsperiode
regierungsperioden$duration <- c(
"1990-94", "1994-96", "1996-97", "1997-00", "2000-03",
"2003-07", "2007-08", "2008-13", "2013-16", "2016-17",
"2017-19", "2019-20", "2020-21", "2021", "Seit 2021"
)
# Erstellen neuer Variable im Dataframe
df01$regper <- NA
# Iterieren durch die Observationen zum feststellen und hinzufügen der richtigen Regierungsperiode in die leere Variable
for (i in 1:nrow(df01)) {
einlangedatum <- as.Date(df01$einlangen[i], format = "%d.%m.%Y")
for (j in 1:nrow(regierungsperioden)) {
startdatum_regper <- as.Date(regierungsperioden$startdatum_regper[j], format = "%d.%m.%Y")
enddatum_regper <- as.Date(regierungsperioden$enddatum_regper[j], format = "%d.%m.%Y")
if (einlangedatum >= startdatum_regper && einlangedatum <= enddatum_regper) {
df01$regper[i] <- regierungsperioden$regper[j]
break
}
}
}
# Alternativen Dataframe erstellen, der die Regierungsperioden Vranitzky III (fehlende Datenlage) und Bierlein (unabhängig) nicht berücksichtigt
regierungsperioden_filtered <- regierungsperioden %>%
filter(regper != "Regierung Vranitzky III" & regper != "Regierung Bierlein")
# Reihenfolge der Regierungsperioden festlegen
regper_order <- c(
"Regierung Vranitzky III",
"Regierung Vranitzky IV",
"Regierung Vranitzky V",
"Regierung Klima",
"Regierung Schüssel I",
"Regierung Schüssel II",
"Regierung Gusenbauer",
"Regierung Faymann I",
"Regierung Faymann II",
"Regierung Kern",
"Regierung Kurz I",
"Regierung Bierlein",
"Regierung Kurz II",
"Regierung Schallenberg",
"Regierung Nehammer"
)
## Filtern der Anfragen auf nur die Anfragen, welche an die Bundesregierung gerichtet wurden
# 1. Identifizieren durch Art des Dokuments: Anfragen, die nicht Dokumenttyp "J" haben
alle_doktyp_J <- all(substr(df01$citation, nchar(df01$citation), nchar(df01$citation)) == "J")
# Ergebnis
if (alle_doktyp_J) {
cat("Alle Doktyps sind J")
} else {
cat("Nicht alle Doktyps sind J")
}
# 2. Filtern der Anfragen, die an den Rechnungshof gerichtet sind (haben Wert NA als Rezipient:in)
df01 <- df01[!is.na(df01$person_2), ]
# Korrigieren bestimmter Einzelfälle in der frak_2 Variable (Rezipient:innen einer Anfrage): Minister:innen die von einer Partei nominiert wurden, im Datensatz aber (teilweise) als unabhängig geführt wurden
frak_2_changes_default <- list(
"Dr. Dieter Böhmdorfer" = "F",
"Dr. Josef Moser" = "V",
"Dr. Karin Kneissl" = "F",
"Dr. Wolfgang Brandstetter" = "V",
"Dr. Wolfgang Mückstein" = "G",
"Mag. Claudia Bandion-Ortner" = "V",
"Mag. Dr. Martin Kocher" = "V",
"Mag. Karin Gastinger" = "F",
"MMag. Dr. Sophie Karmasin" = "V",
"Dr. Andreas Staribacher" = "S")
# Ausnahmen: 2 Minister, die für verschiedene Fraktionen Minister waren, müssen nur teilweise korrigiert werden
frak_2_changes_exception1 <- list(
"Mag. Karl-Heinz Grasser" = "V"
)
frak_2_changes_exception2 <- list(
"Mag. Alexander Schallenberg, LL.M." = "V"
)
# Ändern im Datensatz
for (person_2 in names(frak_2_changes_default)) {
new_frak_2 <- frak_2_changes_default[[person_2]]
df01[df01$person_2 == person_2, "frak_2"] <- new_frak_2
}
# Für Ausnahme 1: Grasser
for (person_2 in names(frak_2_changes_exception1)) {
new_frak_2 <- frak_2_changes_exception1[[person_2]]
condition <- df01$person_2 == person_2 & df01$frak_2 == "A"
df01[condition, "frak_2"] <- new_frak_2
}
# Für Ausnahme 2: Schallenberg
for (person_2 in names(frak_2_changes_exception2)) {
new_frak_2 <- frak_2_changes_exception2[[person_2]]
condition <- df01$person_2 == person_2 & df01$regper != "Regierung Bierlein"
df01[condition, "frak_2"] <- new_frak_2
}
# Hinzufügen einer gov_2 Variable im gleichen Prinzip wie gov, die den Regierungsstatus, von frak_2 (Rezipient:in der Anfrage) ermittelt
# Unabhängige Regierungen / Minister:innen werden hier nicht berücksichtigt
df01$gov_2 <- sapply(seq_along(df01$frak_2), function(i) {
party <- df01$frak_2[i]
if (!is.na(party)) {
date <- as.Date(df01$einlangen[i], format = "%d.%m.%Y")
if (party %in% c("V", "S", "F", "G", "B")) {
if (party == "V") {
party_periods <- govperiods_VP
} else if (party == "S") {
party_periods <- govperiods_SP
} else if (party == "F") {
party_periods <- govperiods_FP
} else if (party == "G") {
party_periods <- govperiods_Gruene
} else if (party == "B") {
party_periods <- govperiods_BZOE
}
if (!is.null(party_periods)) {
get_government_status(party_periods, date)
} else {
0
}
} else if (party == "A") { # Unabhängige Minister:innen
1
} else {
0
}
} else {
0
}
})
# Erneutes Speichern des Dataframes
save(df01, file = "Ihr Dateiname.RData")
## Erstellung eines benutzerdefinierten Themes für die Grafiken
# Laden der Schriftart Lato (stellen Sie zuerst sicher, dass die Schriftart auf dem PC installiert ist)
font_import(paths = "Pfad/zu/Ihrer/Schriftart")
loadfonts(device = "win")
# Erstellen des Themes
custom_theme <- function() {
theme_minimal() +
theme(
plot.background = element_rect(fill = "white", color = NA),
panel.grid.major = element_line(color = alpha("gray", 0.25)),
panel.grid.minor = element_line(color = "white"),
panel.border = element_blank(),
plot.title = element_text(color = "#132843", size = 18, face = "bold", family = "Lato", margin = margin(b = 5), hjust = 0),
plot.subtitle = element_text(color = "#132843", size = 14, family = "Lato", margin = margin(b = 20), hjust = 0),
axis.title.x = element_text(face = "bold", family = "Lato", size = 15, margin = margin(t = 15)),
axis.title.y = element_text(face = "bold", family = "Lato", size = 15, margin = margin(r = 15)),
axis.text = element_text(family = "Lato", size = 12),
legend.text = element_text(family = "Lato", face = "bold", size = 14),
plot.margin = margin(1.2, 0.7, 0.7, 0.7, "cm"),
plot.title.position = "plot",
plot.caption.position = "plot",
plot.caption = element_text(size = 11)
)
}
# Erneutes definieren des Arbeitsverzeichnisses
setwd("Pfad/zu/Ihrem/Arbeitsverzeichnis")
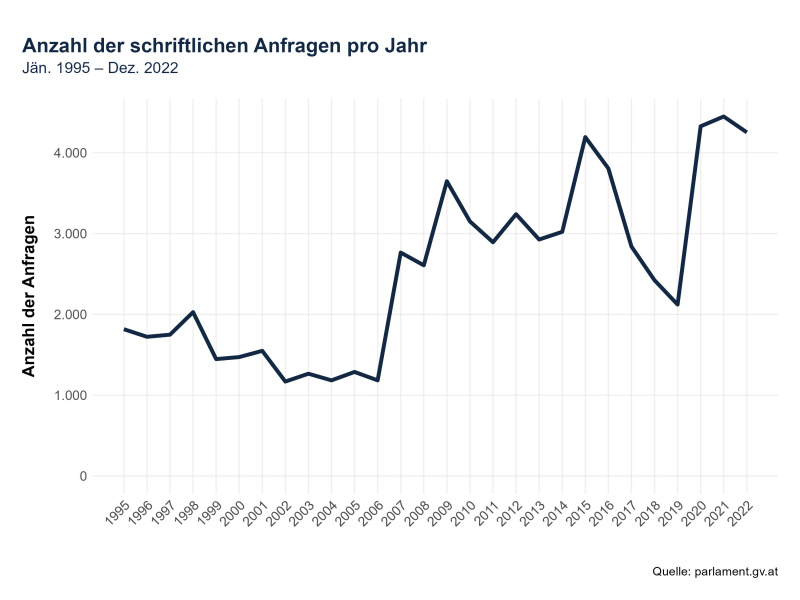
### Analyse 1: Wie hat sich die Häufigkeit schriftlicher Anfragen im Laufe der Jahre verändert?
# Neue Variablen: Anzahl schriftlicher Anfragen nach Jahr und nach Partei nach Jahr
df01 <- df01 %>%
group_by(year) %>%
mutate(freq = n())
df01 <- df01 %>%
mutate(freq_object = 1)
df01 <- df01 %>%
group_by(year, fraktion) %>%
mutate(freq_fraktion = sum(freq_object))
# Die Jahre 1994 und 2023 aufgrund unvollständiger Datenlage ausfiltern
df01_9423 <- df01[!(df01$year %in% c(1994, 2023)), ]
# Das Liniendiagramm erstellen
grafik01 <- ggplot(df01_9423, aes(x = year, y = freq)) +
geom_line(color = "#132843", linewidth = 1.66) +
scale_x_continuous(breaks = seq(1995, 2022, 1)) +
scale_y_continuous(labels = comma_format(big.mark = ".")) +
labs(title = "Anzahl der schriftlichen Anfragen pro Jahr",
subtitle = "Jän. 1995 – Dez. 2022",
x = "",
y = "Anzahl der Anfragen",
caption = "Quelle: parlament.gv.at") +
custom_theme() +
theme(axis.text.x = element_text(angle = 45, hjust = 1, vjust = 1)) +
expand_limits(y = 0)
ggsave("SC05_Grafik01.jpg", grafik01, width = 10, height = 7.5, units = "in", dpi = 300)
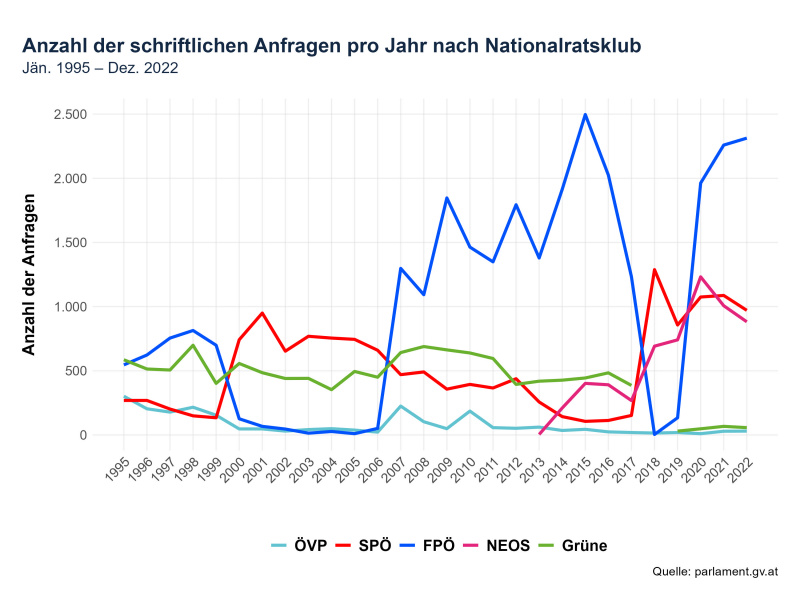
### Analyse 2: Erstellen einer separaten Linie für jede Klub
# Definition von Farben, Reihenfolge und Labels für jeden Parlamentsklub
order_par <- c("V", "S", "F", "N", "G")
labels_par <- c("ÖVP", "SPÖ", "FPÖ", "NEOS", "Grüne")
colors_par <- c("V" = "#62c3d0", "S" = "#FF0000", "F" = "#0052fb", "G" = "#69b12e", "N" = "#e3257b")
# Gruppieren und filtern der Daten: Nur aktuelle Parlamentsklubs, gruppiert nach Anfragen pro Jahr
df01_9423_par <- df01_9423 %>%
filter(fraktion %in% c("V", "S", "F", "G", "N")) %>%
group_by(year, fraktion) %>%
arrange(match(fraktion, order_par)) %>%
summarise(total_anfragen = sum(freq_object))
# Erstellen eines NA Wertes für 2018, da die Grünen nicht im Nationalrat vertreten waren
grüne_2018 <- data.frame(year = 2018, fraktion = "G", total_anfragen = NA)
df01_9423_par <- rbind(df01_9423_par, grüne_2018)
# Sortieren der Fraktionen
df01_9423_par$fraktion <- factor(df01_9423_par$fraktion, levels = order_par)
# Erstellen der Grafik
grafik02 <- ggplot(df01_9423_par, aes(x = year, y = total_anfragen, color = fraktion)) +
geom_line(size = 1.33) +
scale_x_continuous(breaks = seq(1995, 2022, 1)) +
scale_y_continuous(labels = comma_format(big.mark = ".")) +
scale_color_manual(values = colors_par,
labels = labels_par) +
labs(title = "Anzahl der schriftlichen Anfragen pro Jahr nach Nationalratsklub",
subtitle = "Jän. 1995 – Dez. 2022",
x = "",
y = "Anzahl der Anfragen",
caption = "Quelle: parlament.gv.at") +
custom_theme()+
theme(axis.text.x = element_text(angle = 45, hjust = 1, vjust = 1),
legend.position = "bottom",
legend.title = element_blank())
ggsave("SC05_Grafik02.jpg", grafik02, width = 10, height = 7.5, units = "in", dpi = 300)
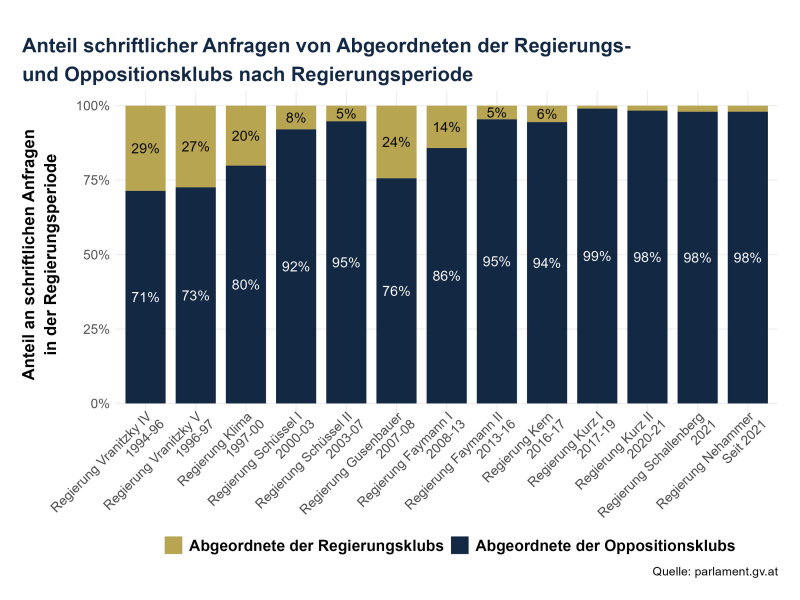
### Analyse 3: Wie viele Anfragen machen Regierungs- vs. Oppositionsklubs?
# Herausfiltern der Anfragen von unabhängigen Abgeordneten
df01_A <- df01 %>%
filter(fraktion != "A")
# Hinzufügen von "NA" zur Vorgängerregierung Kurz I. (bezieht sich auf Übergangsregierung Löger, die vor der Installation der Regierung Bierlein 6 Tage im Amt war)
df01_A$regper[is.na(df01_A$regper)] <- "Regierung Kurz I"
# Herausfiltern von Regierungen: Vranitzky III. (fehlende Daten); Bierlein (unabhänigige Regierung)
df01_A <- df01_A %>%
filter(regper != "Regierung Vranitzky III" & regper != "Regierung Bierlein")
# Transformieren der gov Variable für Regierungs- vs. Oppositionsstatus
df01_govgrouped <- transform(df01_A, group = ifelse(gov == 1, "Abgeordnete der Regierungsklubs", "Abgeordnete der Oppositionsklubs"))
df01_govgrouped$group <- factor(df01_govgrouped$group, levels = c("Abgeordnete der Regierungsklubs", "Abgeordnete der Oppositionsklubs"))
# Anzahl der Anfragen pro Regierungsperiode berechnen
df01_byregper <- df01_govgrouped %>%
group_by(regper) %>%
summarize(regper_count = n()) %>%
ungroup()
# Das Ergebnis in den originalen Dataframe verschieben
df01_govgrouped <- left_join(df01_govgrouped, df01_byregper, by = "regper")
# Daten nach Regierungs- und Oppositionsanfragen nach Regierungsperiode ordnen; auch mit relativen Prozentanteilen
df01_govgrouped_regper <- df01_govgrouped %>%
group_by(regper, group, regper_count) %>%
summarize(count = n()) %>%
ungroup() %>%
mutate(percent = count / regper_count * 100)
# Sortieren der Regierungsperioden
df01_govgrouped_regper$regper <- factor(df01_govgrouped_regper$regper, levels = regper_order)
# Herausfiltern der niedrigen Prozentwerte, nur für die Labelbeschriftungen
df01_govgrouped_percentage <- subset(df01_govgrouped_regper, percent >= 3)
# Erstellen der Grafik mit relativen Prozentanteilen von Regierungs- und Oppositionsanfragen
grafik03 <- ggplot(df01_govgrouped_regper, aes(x = regper, y = percent, fill = group)) +
geom_bar(stat = "identity", position = "stack", width = 0.8) +
geom_text(data = subset(df01_govgrouped_percentage, percent >= 3),
aes(label = paste0(round(percent, 0), "%")),
position = position_stack(vjust = 0.5), size = 4.5,
color = ifelse(df01_govgrouped_percentage$group == "Abgeordnete der Regierungsklubs", "black", "white")) +
labs(x = "",
y = "Anteil an schriftlichen Anfragen\nin der Regierungsperiode",
caption = "Quelle: parlament.gv.at",
title = "Anteil schriftlicher Anfragen von Abgeordneten der Regierungs-\nund Oppositionsklubs nach Regierungsperiode") +
scale_fill_manual(values = c("Abgeordnete der Regierungsklubs" = "#b8a552", "Abgeordnete der Oppositionsklubs" = "#132843")) +
custom_theme() +
scale_y_continuous(labels = scales::percent_format(scale = 1)) +
theme(
legend.title = element_blank(),
legend.position = "bottom",
plot.title = element_text(lineheight = 1.2),
axis.title.x = element_text(margin = margin(t = -40)),
axis.title.y = element_text(lineheight = 1.1),
axis.text.x = element_text(angle = 45, hjust = 1, vjust = 1.15, size = 12)) +
scale_x_discrete(labels = function(x) {
years <- paste(regierungsperioden_filtered$duration)
labels <- paste(x, "\n", years)
return(labels)
})
ggsave("SC05_Grafik03.jpg", grafik03, width = 10, height = 7.5, units = "in", dpi = 300)
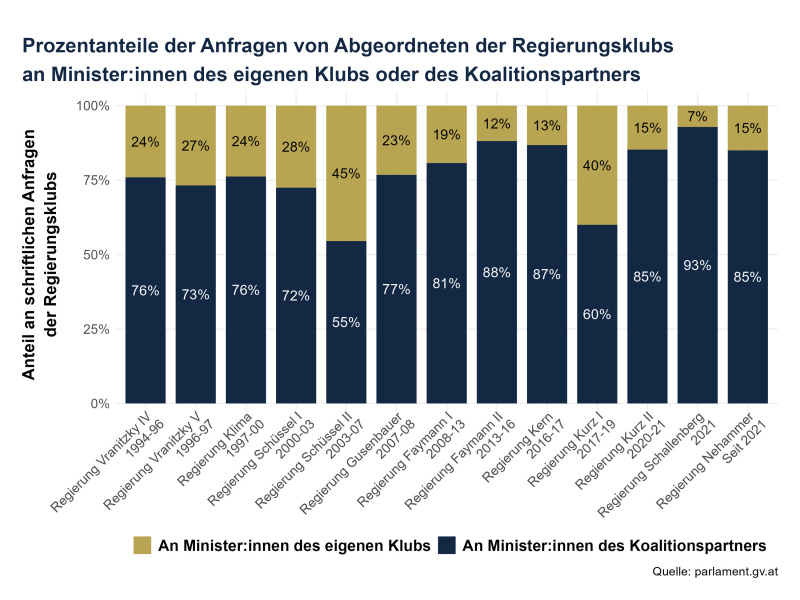
### Analyse 4: Bereichsopposition: Stellen Regierungsparteien an den eigenen Klub oder den Koalitionspartner mehr Anfragen?
# Filtern des Datensatzes nach nur Regierungsparteien (sowohl Quelle als auch Rezipient:in der Anfrage)
df01_onlygov <- df01[df01$gov == 1, ]
df01_onlygov <- df01_onlygov %>%
filter(gov_2 == 1)
# Zusammenfassen von BZÖ und FPÖ, da sie in der Regierungszeit des BZÖ, der Schüssel II Regierung, noch zum gleichen Klub gehörten
df01_onlygov$fraktion <- ifelse(df01_onlygov$fraktion == "B", "F", df01_onlygov$fraktion)
df01_onlygov$frak_2 <- ifelse(df01_onlygov$frak_2 == "B", "F", df01_onlygov$frak_2)
# Gruppieren der Daten nach Anfragen an den eigenen Klub oder Koalitionsklub
df01_onlygov_grouped <- df01_onlygov %>%
group_by(regper, fraktion, frak_2) %>%
summarise(count = n()) %>%
mutate(target_party = ifelse(fraktion == frak_2, "An Minister:innen des eigenen Klubs", "An Minister:innen des Koalitionspartners"))
# Filtern der Vranitzky III Regierung aufgrund unvollständiger Datenlage
# Und filtern von Nikolaus Michalek, da er unabhängiger Minister war
df01_onlygov_grouped <- df01_onlygov_grouped %>%
filter(regper != "Regierung Vranitzky III") %>%
filter(frak_2 != "A")
# Relative Prozentwerte aus den absoluten Zahlen erhalten
# Summe der Anfragen von & an Regierungsparteien berechnen
df01_total_onlygov <- df01_onlygov_grouped %>%
group_by(regper) %>%
summarise(total_count = sum(count))
# In den Basis-Datenframe überspielen und Prozentsätze berechnen
df01_onlygov_grouped <- df01_onlygov_grouped %>%
left_join(df01_total_onlygov, by = "regper") %>%
mutate(relative_percent = (count / total_count) * 100)
# Aggregieren der Daten für jede Regierungsperiode
df01_onlygov_aggregated <- df01_onlygov_grouped %>%
group_by(regper, target_party) %>%
summarize(total_relative_percent = sum(relative_percent, na.rm = TRUE)) %>%
ungroup()
# Balken in der Grafik umdrehen
df01_onlygov_aggregated <- df01_onlygov_aggregated %>%
mutate(target_party = fct_relevel(target_party, "An den eigenen Klub", "An den Koalitionspartner"))
# Sortieren nach Regierungsperiode
df01_onlygov_aggregated$regper <- factor(df01_onlygov_aggregated$regper, levels = regper_order)
# Grafik erstellen
grafik_04 <- ggplot(df01_onlygov_aggregated, aes(x = regper, y = total_relative_percent, fill = target_party)) +
geom_bar(stat = "identity", position = "stack", width = 0.8) +
geom_text(aes(label = paste0(round(total_relative_percent, 0), "%")),
position = position_stack(vjust = 0.5), size = 4.5,
color = ifelse(df01_onlygov_aggregated$target_party == "An Minister:innen des eigenen Klubs", "black", "white")) +
labs(title = "Prozentanteile der Anfragen von Abgeordneten der Regierungsklubs\nan Minister:innen des eigenen Klubs oder des Koalitionspartners",
x = "",
y = "Anteil an schriftlichen Anfragen\nder Regierungsklubs",
caption = "Quelle: parlament.gv.at") +
scale_fill_manual(values = c( "An Minister:innen des Koalitionspartners" = "#132843", "An Minister:innen des eigenen Klubs" = "#b8a552")) +
custom_theme() +
scale_y_continuous(labels = scales::percent_format(scale = 1)) +
theme(
legend.title = element_blank(),
legend.position = "bottom",
plot.title = element_text(lineheight = 1.2),
axis.title.x = element_text(margin = margin(t = -40)),
axis.title.y = element_text(lineheight = 1.1),
axis.text.x = element_text(angle = 45, hjust = 1, vjust = 1.15, size = 12)) +
scale_x_discrete(labels = function(x) {
years <- paste(regierungsperioden_filtered$duration)
labels <- paste(x, "\n", years)
return(labels)
})
ggsave("SC05_Grafik04.jpg", grafik_04, width = 10, height = 7.5, units = "in", dpi = 300)